



Целью работы является построение и исследование метода выполнения вертикальных групповых арифметических операций над целыми двоичными числами без вычисления переноса на всех шагах вычислений на основе подхода, изложенного в [1]. Рассматривается потоковая обработка вначале слагаемых, затем сомножителей. Вычисления организуются так, чтобы алгоритм обработки был инвариантен относительно веса вертикального среза и числа разрядов операндов, при этом с помощью сохранения промежуточных данных исключается вычисление переноса. В границах минимизации временной сложности арифметической обработки потока требуется выполнить оценки роста числового диапазона данных в зависимости от количества шагов обработки. Для реализации метода предлагается концепция параллельного вычислителя, позволяющего архитектурно ограничить рост числового диапазона.
Вертикальная обработка потока слагаемых. На вход метода подаются двоичные полиномы
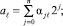
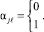
Требуется вычислить сумму
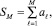
где M – произвольное натуральное, с разбиением на группы по N чисел:
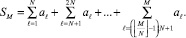
Выделяется k-я группа слагаемых:
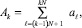
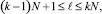
которая подвергается одному шагу вертикальной обработки. Все операции шага выполняются инвариантно относительно номера разряда двоичных слагаемых, синхронно и взаимно независимо, представляют собой суммирование по вертикали всех коэффициентов j-го разряда всех слагаемых группы 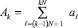 при каждом j = const. За результат принимается двоичный полином, коэффициенты которого располагаются по диагонали справа налево, сверху вниз согласно их весу (диагональная запись). Диагональная запись по всем разрядам образует промежуточную сумму двоичных полиномов. На шаге k + 1 к входному набору слагаемых добавляется промежуточная сумма, полученная на k-м шаге, образуя единый входной набор для выполнения k + 1-го шага. В [1] доказана.
при каждом j = const. За результат принимается двоичный полином, коэффициенты которого располагаются по диагонали справа налево, сверху вниз согласно их весу (диагональная запись). Диагональная запись по всем разрядам образует промежуточную сумму двоичных полиномов. На шаге k + 1 к входному набору слагаемых добавляется промежуточная сумма, полученная на k-м шаге, образуя единый входной набор для выполнения k + 1-го шага. В [1] доказана.
Теорема 1. При вычислении суммы SM посредством рассматриваемого способа для сколь угодно большого M и произвольного N количество 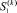 промежуточных слагаемых на выходе k-го шага ограничено константой, не зависящей от k, –.
промежуточных слагаемых на выходе k-го шага ограничено константой, не зависящей от k, –.
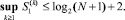
При этом на каждом шаге имеет место бесконфликтность распространения всех переносов, которая понимается как невозможность прихода двух единиц переноса в один и тот же разряд одного и того же промежуточного слагаемого.
Оценка и ограничение роста числового диапазона при сложении. С целью ограничения в дальнейшем роста диапазона данных набор полиномов промежуточной суммы рассматривается в качестве входного, к нему применяется тот же прием суммирования, набор сжимается до промежуточной суммы с меньшим числом слагаемых. В силу небольшого значения 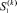 за малое число повторов данного сжатия промежуточное число слагаемых сжимается до двух, образуя двухрядный код суммы. В [2] доказана
за малое число повторов данного сжатия промежуточное число слагаемых сжимается до двух, образуя двухрядный код суммы. В [2] доказана
Теорема 2. В условиях теоремы 1 найдется 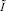 , такое, что для всех
, такое, что для всех 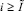 количество старших разрядов, прирастающих на шаге рассматриваемого метода, не превысит единицы.
количество старших разрядов, прирастающих на шаге рассматриваемого метода, не превысит единицы.
Сравнительно малый рост диапазона слагаемых промежуточных сумм можно дополнительно ограничить за счет структуры данных, учитывающей специфику метода. Именно, при отсчете справа налево номеров 0, 1, ..., n разрядов входных слагаемых, те разряды сжатой двухрядной суммы, которые имеют вес больше n, отсоединяются (для подсуммирования в дальнейшем) в отдельный новый массив. Он формируется из отсоединенных двухрядных наборов слагаемых, пополняясь на каждом новом шаге обработки текущего набора входных слагаемых с присоединенной двухрядной промежуточной суммой, и образует матрицу. Когда число строк матрицы сравняется с числом строк текущего входного набора, эта матрица подвергается такой же обработке, как набор Ak. От результата снова отсоединяются старшие разряды в новую матрицу, а старая заполняется по мере шагов обработки новых входных наборов. Обработка ведется параллельно по всем разрядам всех слагаемых всех матриц. Их количество растет, но рост замедляется по весу разрядов аналогично замедлению счетчика при росте единиц измерения.
Физическое замедление роста диапазона в границах предложенной структуры данных показывают следующие оценки. Пусть T0 – время обработки входного набора из N + 2 (с учетом промежуточной суммы) двоичных слагаемых разрядности n + 1, пусть t1 = T0. Тогда время формирования первой матрицы определяется тем, что она заполняется парами по два двоичных слагаемых из отсоединенных старших разрядов за 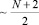 суммирований входного набора. Отсюда за
суммирований входного набора. Отсюда за 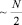 суммирований соответственно, за время
суммирований соответственно, за время 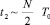 , произойдет заполнение первой матрицы. По индукции переход к общему случаю влечет для заполнения матрицы с номером k + 1 оценку времени
, произойдет заполнение первой матрицы. По индукции переход к общему случаю влечет для заполнения матрицы с номером k + 1 оценку времени 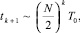 , где k = 1, 2, ..., M. Оценка временной сложности T0 базисного алгоритма с подстановкой в последнее выражение показывает [3], что непрерывная работа параллельного вычислителя, реализующего данный способ в формате с фиксированной точкой, возможна без округления в течение многих лет.
, где k = 1, 2, ..., M. Оценка временной сложности T0 базисного алгоритма с подстановкой в последнее выражение показывает [3], что непрерывная работа параллельного вычислителя, реализующего данный способ в формате с фиксированной точкой, возможна без округления в течение многих лет.
Вертикальная обработка потока сомножителей. На основе рассматриваемого метода вертикального суммирования организуется умножение неограниченного потока двоичных сомножителей без вычисления переноса. Сформированная по «школьной» схеме умножения матрица слагаемых для двух двоичных сомножителей подается на вход изложенного метода, который применяется к данному набору слагаемых и формирует на выходе промежуточную (не вычисленную) сумму полноразрядных двоичных слагаемых. Умножение на следующий сомножитель выполняется по дистрибутивности. Процесс воспроизводится для каждого сомножителя потока. Пусть требуется найти произведение
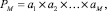
где все сомножители заданы и имеют вид
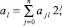
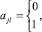
M выбрано произвольно. Шаг с номером k поразрядно-параллельного вертикального суммирования ставится в соответствие k-му умножению вида
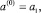
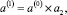 ...,
..., 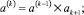 k = 1, 2, ..., M – 1.
k = 1, 2, ..., M – 1.
Для данного шага формируется k-я «школьная» схема (образуемая умножением первого сомножителя на текущий разряд второго с соответственным весу сдвигом на разряд влево). Набор двоичных слагаемых, сформированный по этой схеме, принимается за входной набор для k-го шага описанного выше метода вертикального группового сложения. За результат сложения принимается k-й промежуточный набор слагаемых, который интерпретируется как результат k-го произведения. В [1] доказана.
Теорема 3. При вычислении рассматриваемым способом PM для сколь угодно большого M и произвольного числа разрядов n + 1 количество 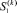 слагаемых k-го промежуточного набора ограничено константой, не зависящей от k, –
слагаемых k-го промежуточного набора ограничено константой, не зависящей от k, –
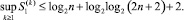
При этом на каждом шаге имеет место бесконфликтность распространения всех переносов.
Отсюда за малое число шагов промежуточная сумма может быть сжата до двух слагаемых.
Оценка роста числового диапазона при умножении. Ниже приводятся оценки роста числа разрядов произведения в зависимости от числа сомножителей и соответственно числа шагов умножения. В [4] даны доказательства утверждений, приводимых в качестве основы для изложения способа выполнения операций с фиксированной точкой без округления. Пусть правая часть неравенства из теоремы 3 обозначена 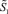 . Справедлива
. Справедлива
Теорема 4. Начиная с некоторого номера шага k = k1 рассматриваемого метода вертикального умножения, прирост 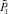 числа разрядов по отношению к начальному шагу будет удовлетворять неравенству:
числа разрядов по отношению к начальному шагу будет удовлетворять неравенству:
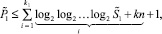
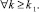
Следствие 1. Суммарный прирост P2 числа разрядов по i шагам сжатия текущего входного набора до двухрядного кода имеет оценку .
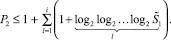
Сумма справа конечна, поскольку сжатие продолжается только до двухрядного кода: i ≤ I, при котором
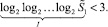
С учетом того, что на каждом шаге умножения «школьная» схема увеличивает число разрядов входного набора на n, имеет место [4]
Теорема 5. Суммарное число P3 разрядов по всем J шагам рассматриваемого метода умножения при сжатии каждого входного набора до двух промежуточных слагаемых оценивается из неравенства: 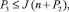 где P2 оценивается согласно следствию 1.
где P2 оценивается согласно следствию 1.
Для дальнейшего уточняется общее число разрядов произведения и прирост числа разрядов по шагам. Пусть снова рассматриваются 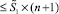 слагаемых входного набора, и в них выделены те старшие разряды, которые соответствуют сдвигу сомножителя на n разрядов влево на каждом шаге формирования набора «школьных» схем умножения. В результате первого шага рассматриваемого вертикального суммирования от старшего из выделенных разрядов возникнет прирост P количества старших разрядов, удовлетворяющий (в силу диагональной записи суммы вертикального среза) неравенству:
слагаемых входного набора, и в них выделены те старшие разряды, которые соответствуют сдвигу сомножителя на n разрядов влево на каждом шаге формирования набора «школьных» схем умножения. В результате первого шага рассматриваемого вертикального суммирования от старшего из выделенных разрядов возникнет прирост P количества старших разрядов, удовлетворяющий (в силу диагональной записи суммы вертикального среза) неравенству: 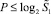 . Очевидно, от разряда, предшествующего старшему, прирост составит
. Очевидно, от разряда, предшествующего старшему, прирост составит 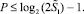 По индукции, от разряда, предшествующего старшему на i разрядов вправо, получится прирост:
По индукции, от разряда, предшествующего старшему на i разрядов вправо, получится прирост: 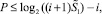 тем более,
тем более, 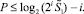 В результате прирост числа разрядов в отсчете от любого разряда, предшествующего старшему разряду входного набора, всегда оценивается из неравенства
В результате прирост числа разрядов в отсчете от любого разряда, предшествующего старшему разряду входного набора, всегда оценивается из неравенства 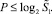 Количество
Количество 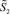 слагаемых промежуточной суммы, получивших рассмотренный прирост, аналогично, оценивается из неравенства:
слагаемых промежуточной суммы, получивших рассмотренный прирост, аналогично, оценивается из неравенства: 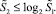
Пусть выполняется сжатие промежуточной суммы до двухрядного кода. Тогда на втором шаге сжатия роль 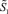 по отношению к приросту разрядности будет играть
по отношению к приросту разрядности будет играть 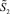 из предыдущего неравенства, поэтому
из предыдущего неравенства, поэтому 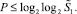 Для шага с номером k ≥ 2 по индукции оправдывается оценка
Для шага с номером k ≥ 2 по индукции оправдывается оценка 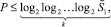 где начиная с некоторого k0 = const, для всех k ≥ k0 правая часть не превзойдет единицы. Отсюда вытекает
где начиная с некоторого k0 = const, для всех k ≥ k0 правая часть не превзойдет единицы. Отсюда вытекает
Лемма 1. В рассматриваемом способе умножения 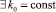 такое, что прирост
такое, что прирост 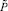 числа разрядов, отсчитываемый от старшего разряда текущих слагаемых на входе k-го шага сжатия, удовлетворяет неравенству:
числа разрядов, отсчитываемый от старшего разряда текущих слагаемых на входе k-го шага сжатия, удовлетворяет неравенству: 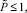
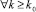 .
.
Поскольку входной набор умножения формируется по дистрибутивности относительно слагаемых промежуточной суммы, то к рассмотренному приросту добавляется n разрядов сдвига вследствие структуры «школьной» схемы. Отсюда с учетом леммы 1 вытекает
Теорема 6. В рассматриваемом способе умножения с двухрядной промежуточной суммой 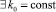 такое, что общий прирост
такое, что общий прирост 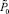 числа разрядов на шаге умножения оценивается из неравенства:
числа разрядов на шаге умножения оценивается из неравенства: 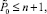
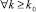 .
.
Оценка теоремы 6 сопоставима с приростом числа разрядов обычного умножения с распространением переноса, однако рассмотренный метод исключает вычисление переноса и параллелен по всем разрядным срезам.
Концептуальная архитектура параллельного вычислителя. Для реализации потокового выполнения рассмотренных операций возможна следующая структура параллельного процессора.
С учетом предложенной выше структуры данных для группового сложения каждый этап сжатия текущей матрицы отделенных двухрядных слагаемых предлагается выполнять на сопоставленной именно этой матрице группе процессорных элементов (ПЭ). При этом каждый ПЭ сопоставляется одному и только одному разряду слагаемых и выполняет вертикальное суммирование одноразрядных чисел столбца матрицы с зафиксированным разрядным срезом. Поразрядно-параллельная работа ПЭ синхронно продолжается до сжатия слагаемых матрицы в двухрядный код промежуточной суммы. В результате параллельной по всем матрицам и всем разрядным срезам работы ПЭ процесс обработки старших разрядов будет замедляться пропорционально замедлению выхода старших разрядов при переходе от i-й к i + 1-й матрице. При этом обработка всех входных слагаемых потока будет происходить в темпе поступления и суммирования непосредственно самого входного набора.
Для выполнения вертикального умножения на параллельном процессоре с данной структурой предлагается следующая модификация обработки. Умножение каждой не просуммированной пары двоичных чисел двухрядного кода текущего произведения будет выполняться на взаимно однозначно сопоставленных разрядным срезам ПЭ: i-й справа налево разрядный срез обрабатывается i-м ПЭ. После формирования по дистрибутивности «школьных схем» изложенным способом выполняется поразрядно-параллельное вертикальное суммирование, синхронно продолжающееся до сжатия промежуточной суммы в двухрядный код. В отличие от матричной структуры, использованной для сложения, умножение на новый сомножитель двухрядного кода текущего произведения реализуется, как если бы каждый такой двухрядный код был преобразован в линейный массив с сохранением позиционной записи двоичного числа.
В линейных алгоритмах изложенный способ как в случае сложения, так и при умножении отличается тем [5, 6], что не предполагает вычисления переноса и выполнения округления. Распространение способа на бинарные полноразрядные операции рассматривается в [7, 8], на этой основе предложенная архитектура вычислителя может быть модифицирована для реализации алгоритмов с ветвлениями.
Заключение
Изложен метод вертикального поразрядно-параллельного сложения и умножения потока целых двоичных чисел, отличающийся тем, что в качестве результата используется не вычисленная промежуточная сумма в виде двухрядного кода, при этом не требуется выполнять вычисление переноса. Даны оценки роста разрядности результатов сложения и умножения. На основе инвариантности обработки всех разрядов рассматриваемые групповые операции допускают реализацию с помощью поразрядно-параллельно работающих процессорных элементов. В случае реализации линейных алгоритмов не предполагается выполнять округление, и за счет параллелизма может достигаться существенное повышение точности арифметической обработки.
Рецензенты:
Турулин И.И., д.т.н., профессор кафедры АСНИиЭ ТТИ ЮФУ, г. Таганрог;
Карелин В.П., д.т.н., профессор, заведующий кафедрой математики и информатики ТИУиЭ, г. Таганрог;
Бичурин М.И., д.ф.-м.н., зав. кафедрой проектирования и технологии радиоаппаратуры Новгородского государственного университета, г. Великий Новгород.
Работа поступила в редакцию 18.06.2012.
Библиографическая ссылка
Ромм Я.Е., Иванова А.С. ВЕРТИКАЛЬНЫЕ ГРУППОВЫЕ АРИФМЕТИЧЕСКИЕ ОПЕРАЦИИ НАД ЦЕЛОЧИСЛЕННЫМИ ДАННЫМИ БЕЗ ВЫЧИСЛЕНИЯ ПЕРЕНОСА // Фундаментальные исследования. – 2012. – № 11-4. – С. 960-964;URL: https://fundamental-research.ru/ru/article/view?id=30692 (дата обращения: 26.04.2024).