



Постоянно увеличивающийся научный интерес к процессам эффективного хранения, обработки и защиты информации, наблюдаемый в настоящее время, обусловливается, прежде всего, беспрецедентным ростом данных. Совершенствование систем хранения и резервного копирования в настоящее время в большей степени направлено на использование вычислительных ресурсов для повышения эффективности работы. Активно развивающаяся технология дедупликация данных (англ. deduplication) служит для снижения объема хранимых данных посредством определения и удаления избыточных идентичных элементов в разных копиях и версиях данных. В то же время, как правило, процессы дедупликации создают дополнительную вычислительную нагрузку.
Дедупликация данных производится на различных уровнях: на уровне файлов (англ. file-level deduplication, далее FD), когда дублирующие файлы исключаются из хранения, а также на уровне блоков. Дедупликация на блочном уровне может быть разделена на два основных направления: дедупликация по блокам фиксированного размера (англ. static chunking, далее SC); дедупликация по блокам различной длины, которая зависит от содержания данных (англ. content defined chunking, далее CDC). Считается, что дедупликация на файловом уровне в среднем снижает объем данных резервного копирования в три, четыре раза. Одно из исследований [7], основанное на масштабном, комплексном анализе данных, выявило, что применение дедупликации на уровне файлов вместе с использованием разреженных файлов (функциональная особенность файловых систем, англ. sparse files) является эффективным средством снижения объема хранимых данных, в том числе и в случае резервного копирования. Так, дедупликация с блоками переменной длины с использованием метода Рабина позволяет получить на 18–20 % лучшую эффективность, чем файловая дедупликация, а блочная дедупликация с фиксированной – на 11 %. При исследовании дедупликации с применением инкрементного резервного копирования с созданием еженедельных полных копий блочная дедупликация с использованием метода Рабина оказалась на 32 % эффективнее пофайловой. Результаты данного исследования позволяют сделать вывод о том, что эффективность файловой дедупликации данных была в целом недооценена ранее. В то же время файловая дедупликация требует намного меньшую вычислительную нагрузку и более проста в реализации.
Увеличение производительности дедупликации является актуальной целью многочисленных исследований в области вычислительной техники. В представленной работе предлагается оригинальная технология организации дедупликации при копировании данных. В отличие от существующих решений [3, 6] в разрабатываемом подходе предлагается гибридный адаптивный способ дедупликации, нацеленный на совместное использование пофайловой и различных вариантов блочной дедупликации для нахождения эффективного баланса снижения вычислительной нагрузки при сохранении достаточно высокого уровня дедупликации.
Способ адаптивной дедупликации данных
Эффективность дедупликации зависит от типа обрабатываемых данных [5]. Так, применение дедупликации с блоками различной длины (CDC) наименее эффективно в случае с зашифрованными и упакованными данными, например, в случае с аудио- и видеоформатами лучшим вариантом является дедупликация на файловом уровне (FD) или с фиксированными блоками (SC) большого размера. В случае, когда известно, какие данные передаются на вход в систему дедупликации, в зависимости, например, от типа файла, размера и его атрибутов система может различным образом включаться в его обработку. Таким образом, адаптация параметров дедупликации в зависимости от типа файловых данных предоставляет возможности для повышения эффективности работы системы.
В целях исследования эффективности предложенного способа применения гибридного механизма дедупликации разработана программная система [1], в которой источниками данных для модуля адаптивного выбора метода и параметров дедупликации являются файловые метаданные, пользовательские и системные настройки, определяющие методы обработки для известных типов файлов, статистическая информация, накопленная системой (рис. 1). Параметры копирования и дедупликации доступны для коррекции пользователем в настраиваемых профилях каждой задачи копирования.
Адаптация системы происходит с использованием статистики, основанной на информации каталога системы резервного копирования. Например, в случае, если при резервировании некоторого файла была автоматически выбрана FD-дедупликация, но при выполнении последующих операций резервирования файл подвергается частым изменениям, системой в результате анализа может быть принято решение об изменении применяемого способа дедупликации.
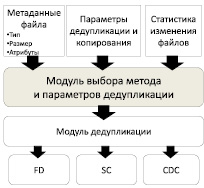
Рис. 1 Иллюстрация работы модуля выбора метода и параметров дедупликации
В предложенном способе блочная дедупликация данных с размером блоков, зависящих от данных (CDC), выполняется с использованием метода Рабина. При выполнении разметки каждого нового блока используется «скользящее окно» (рис. 2), для которого рассчитывается хеш-значение f. Выполнение критерия в общем виде f mod D = r определяет конец нового блока [3]. Использованы следующие обозначения, D – делитель, r – предустановленные значения, зависящие от алгоритма.
На рис. 2 изображено «скользящее окно» при разметке нового блока с применением плавающих контрольных сумм. Для разбиения файла на блоки используется окно постоянного размера. В каждой позиции рассчитывается значение сигнатуры f. Процесс повторяется до завершения разметки всего файла. Для расчета значений хеша по блокам в системе используется алгоритм SHA.
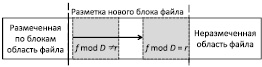
Рис. 2 Процедура разметки файла на блоки
Индекс размещения данных
В целях повышения производительности процесса дедупликации разработан специализированный алгоритм группировки индексов, основанный на принципе объединения файлов в классы. Так, индекс размещения данных разработанной системы разбивается по уровням: индекс файлов, классов подобия и индекс блоков данных (рис. 3). Для каждого файла в системе создается запись в индексе файлов, хранящая значение хеш-функции, ссылку на индекс блоков данных, где в случае, когда используется блочная дедупликация, хранится информация об имеющихся блоках с указанием хеш-значений. При использовании файловой дедупликации данные хранятся в едином блоке для обеспечения унификации работы системы и индекса размещения данных.
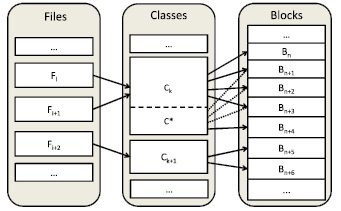
Рис. 3 Принципиальная схема индекса размещения данных
Ключевым элементом построения индекса блоков данных является применяемый принцип разбиения множества обрабатываемых файлов на классы. Так, в случае, когда логическое разделение блоков по файлам известно, предлагается применение группировки блоков по классам подобных файлов. При этом для оценки степени подобия используется индекс Жаккарда и обобщение теоремы Бродера [4]. Так, если S1 и S2 – два множества блоков двух файлов, H(S1) и H(S2) – хеш-блоков, тогда:
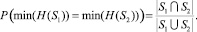
Данное выражение показывает, что вероятность совпадения минимальных хеш-элементов множеств S1 и S2 равна индексу Жаккарда. Для возможности определения подобных файлов информация о минимальном хеш-элементе хранится в файловом индексе. Имеющиеся исследования [1, 2] показывают, что описанный выше подход может быть использован с высокой точность без необходимости применения техники перебора. Пример, изображенный на рис. 3, иллюстрирует частный случай размещения класса подобных файлов. Так, при появлении нового файла Fi+1, относящегося к классу Ck, дополнительного элемента в индексе классов не создается. Вместо этого различающиеся блоки (Bn+4 на рисунке) помещаются в хранилище, а в индексе блоков добавляются необходимые ссылки. Для повышения производительности индекс файлов постоянно располагается в оперативной памяти, в то же время индексы блоков данных в целях обеспечения экономии памяти загружаются и остаются в кэше в зависимости от потребности системы.
Группировки индексов блоков, которые с высокой вероятностью будут затребованы вместе, последовательно или с небольшим интервалом также позволяют увеличить производительность. Так, при поиске идентификатора нового блока выполняется поиск в группе предыдущего совпадения. В отличие от известного подхода [3] нами предлагается схема, где разбиение по блокам является опциональным. Это обобщение позволяет реализовать гибридный подход, где в одном ряду может быть использована как файловая, так и блочная дедупликация в зависимости от работы заданных параметров.
Заключение
Для возможности проведения комплексного анализа характеристик эффективности дедупликации и производительности разработан прототип программной системы, средствами которой можно проводить исследование разных аспектов процессов резервного копирования и восстановления как на моделируемых, так и на реальных данных [1]. В системе реализовано полное, инкрементное, дифференциальное и другие основные виды резервного копирования, предусмотрены возможности архивирования резервных копий, автоматизированное восстановление. В результате произведенных экспериментов было подтверждено, что уровень дедупликации предложенного способа при произведении инкрементного резервного копирования в среднем выше файловой и SC-дедупликации на 18 %, и на некоторых исходных файловых данных системы приближается к уровню CDC-дедупликации. Применение принципа группировки блоков и подобных файлов в индексе показало повышение скорости работы поиска по индексу данных в среднем на 24 % по проведенным экспериментам.
Важнейшими направлениями дальнейшей работы являются формальное описание алгоритма адаптированного изменения параметров дедупликации, детальное экспериментальное исследование количественных зависимостей характеристик эффективности предложенного способа дедупликации от массива используемых данных для копирования и публикация результатов. Помимо этого предложенная концепция применения накопленной статистики работы системы резервного копирования для адаптивного управления системой дедупликации является также малоизученной и нуждается в экспериментальных данных.
Описанный в работе подход позволяет применять технологию дедупликации не только с использованием выделенных вычислительных серверных мощностей на крупных предприятиях, но и в бытовых персональных компьютерах и даже на мобильных устройствах. Требуемый баланс между уровнем вычислительной нагрузки и эффективностью дедупликации достигается за счет адаптивного применения различных способов дедупликации на файловом и блочном уровнях. Практическая значимость работы заключается в возможности внедрения предложенного способа при разработке систем копирования и хранения данных.
Рецензенты:
Щенников В.Н., д.ф.-м.н., профессор, заведующий кафедрой дифференциальных уравнений, ФГБУ ВПО «Мордовский государственный университет им. Н.П. Огарева», г. Саранск;
Панфилов С.А., д.т.н., профессор, заведующий кафедрой теоретической и общей электротехники, ФГБУ ВПО «Мордовский государственный университет им. Н.П. Огарева», г. Саранск.
Работа поступила в редакцию 19.07.2013.
Библиографическая ссылка
Казаков В.Г., Федосин С.А., Плотникова Н.П. СПОСОБ АДАПТИВНОЙ ДЕДУПЛИКАЦИИ С ПРИМЕНЕНИЕМ МНОГОУРОВНЕВОГО ИНДЕКСА РАЗМЕЩЕНИЯ КОПИРУЕМЫХ БЛОКОВ ДАННЫХ // Фундаментальные исследования. – 2013. – № 8-6. – С. 1322-1325;URL: https://fundamental-research.ru/ru/article/view?id=32130 (дата обращения: 25.04.2024).