



Важность и значимость анализа и обработки текстовых и других слабоструктурированных данных постоянно возрастает. В связи с широким распространением систем электронного документооборота, социальных сетей, сетевых информационных порталов, персональных сайтов это становится особенно важным и как техническая задача, и как значимая часть взаимодействия людей в современном информационном мире. При работе с большими объемами текстовой информации постоянно возникают новые проблемы, которые требуют своего решения. В настоящее время ведутся активные исследования в данной области, однако существует ряд нерешённых проблем, связанных с созданием общесистемных подходов к представлению текстов.
Все исследования последнего времени в области интеллектуального анализа текстов в той или иной степени опираются на системный подход к естественному языку. Все более распространяющаяся тенденция – рассматривать как некую системную целостность текст полностью или даже корпус текстов. Применение системного подхода оправдано, поскольку язык обладает всеми свойствами и характеристиками, присущими сложным системам. Однако он обладает и своими особенностями. Систему языка можно определить как некоторое основополагающее свойство языка, обусловленное его сложным составом и сложными функциональными задачами.
Можно выделить следующие основные свойства и фундаментальные качества естественного языка [3]:
– принципиальная нечеткость значения языковых выражений;
– динамичность языковой системы;
– образность номинации, основанная на метафоричности;
– семантическая мощь словаря, позволяющая выражать любую информацию с помощью конечного инвентаря элементов;
– гибкость в передаче эксплицитной и имплицитной информации;
– разнообразие функций, включающее коммуникативную, когнитивную, планирующую, управляющую, обучающую, эстетическую и другие;
– специфическая системность и разделение языка на уровни и подсистемы.
Текст является одним из наиболее четких и значимых выражений естественного языка, поэтому на основании перечисленных свойств и качеств языка можно определить основные теоретические положения, опираясь на которые можно строить системы анализа и обработки текстовых структур. К таким основам относятся системное и потоковое представление текстов, теория сжатия и теория нечеткости.
Системное представление текстовых структур
Системное представление текстов предполагает формализацию и представление в явной структуре глубинных свойств и характеристик текста и построение его моделей. Достаточно очевидной является иерархическая организация текста, схема которой представлена на рис. 1, причем на каждом уровне иерархии текст структурирован не только под влиянием законов этого уровня, но и законами вышележащих уровней.
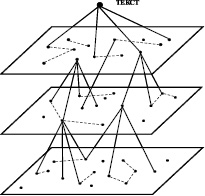
Рис. 1. Иерархическое представление текста
Иерархическая модель может отражать разные параметры текстовой структуры. Одно из представлений – выделение уровней букв, слов и предложений [6]. Структура целого текста определяет не только связи между предложениями, но и связи между словами, а также в некоторой степени связи между элементами слова (буквами и слогами).
Аналогично в [9] построена система смыслового содержания текста. Нижним уровнем также является уровень знаков (буквы, цифры и т.п.), следующий уровень – уровень отдельных слов без учета их значимости в тексте, третий уровень – уровень терминов и последний – уровень понятий и онтологий. В структурно-иерархической словарной модели текста все уровни представляют собой значимые структуры. В иерархической системе смыслового содержания нижние уровни имеют гораздо меньшее значение и используются в основном как вспомогательные элементы для составления объектов более высокого уровня.
При такой модели элементы высшего уровня могут содержать тематически связанные слова и термины, прямо не встречающиеся в текстах или содержащиеся не во всех рассматриваемых текстах, относящихся к данной содержательной области. Именно уровень понятий позволяет решать вопросы, связанные с синонимией и полисемией терминов в текстах. Например, предложена плекс-грамматика [4], позволяющая уменьшить неоднозначность семантических моделей высказываний. С учетом контекстов употребления выражений использование лингвистических отнологий позволяет извлекать сущности и тематические цепочки при рассмотрении разного рода текстов [1].
Потоковое представление текстовых структур
Потоковое представление текстовых данных широко распространено при описании и анализе динамически изменяющихся массивов текстов в Интернете. Текстовые потоки – коллекции документов или сообщений, которые постоянно генерируются и распространяются. Подход, основанный на потоковом принципе представления текстовых данных (stream-based), может быть использован и при анализе больших текстовых объектов, таких как художественные тексты или научные публикации. Весь текст представляют как непрерывный поток текстовой информации, среди которых могут быть выделены его отдельные структурные элементы.
Текст X можно рассматривать как последовательность (поток) из n элементов x1, x2, ..., xn некоторого алфавита Q, при этом длина текстовой строки (текста) 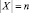 [7]. Элементом текста xn может быть как одиночный текстовый символ, так и слово, грамматический класс, любая группировка или подстрока символов текста. Схематично потоковое представление текстов изображено на рис. 2.
[7]. Элементом текста xn может быть как одиночный текстовый символ, так и слово, грамматический класс, любая группировка или подстрока символов текста. Схематично потоковое представление текстов изображено на рис. 2.
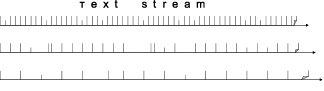
Рис. 2. Потоковое представление текста для разных элементов
При рассмотрении текстовых потоков на передний план выходят задачи кластеризации и классификации, а также прогнозирования и поиска закономерностей для определения возможных изменений в тематике текстовых потоков и направлений развития текстов. Также необходимо выявление и отслеживание появления различных текстов или их частей с отличной от прогнозируемой тематикой.
Теория сжатия и Колмогоровская сложность
Задача сжатия (компрессии) информации возникла с появлением первых трудностей при передаче большого объема информации и во многом связана с ограничениями на возможности хранения информации, требованиями к быстрому доступу и передаче в условиях ограниченной пропускной способности. В последнее время возможности хранения и передачи информации возросли, но и количество информации продолжает увеличиваться, поэтому методы и подходы к сжатию данных постоянно развиваются и совершенствуются.
Говоря о текстовых данных и текстовых структурах, необходимо учитывать их особенности, которые позволяют использовать алгоритмы сжатия для дальнейшего анализа текстов. Для информации в текстовом виде характерны следующие особенности, на основе которых проектируются эффективные алгоритмы сжатия:
– последовательное представление;
– избыточность языка и текста.
Последовательное представление данных связано с природой самого текста, который представляется в виде некоторого потока элементов. Причем, опираясь на иерархическую модель текста, можно говорить о потоке (последовательности) данных разных уровней: последовательность букв, последовательность слогов, слов, словосочетаний и т.п. Таким образом, основная идея рассмотрения текстов как потока данных – рассмотрение зависимости появления очередного элемента текста от предшествующих.
Избыточность текста. Избыточность присуща любым текстам и языкам. Избыточность языка в целом объясняется главной функцией языка – коммуникативной, то есть язык избыточен по своей природе, но позволяет легко общаться. Известно, что избыточность текста в большей степени вызвана гласными буквами: текст, написанный без гласных, может быть понят. Если рассматривать лингвистические, языковые причины избыточности, то также можно указать различные функции и категории падежей, морфонологические (связанные с производным словообразованием) явления и т.п. Избыточность художественных текстов также связана с коммуникативностью в обществе, то есть желанием автора некоторым образом повлиять на читателя, вызвать те или иные эмоции, донести некоторую мысль. Но именно избыточность информации, как текстовой, так и любой другой, позволяет эффективно применять различные алгоритмы сжатия, путем избавления от избыточности различными способами.
Как правило, соседние или близко расположенные элементы изображения близки по цвету и интенсивности, а следующие друг за другом кадры отличаются только некоторыми элементами. Текстовые объекты также необходимо рассматривать с позиций контекстного моделирования (context modeling): с одной стороны, любой текст представляет собой поток данных, с другой – для текстов на естественном языке появление любого элемента во многом зависит от предшествующих элементов.
Основу возможности применения алгоритмов сжатия для оценки близости двух объектов составляет понятие Колмогоровской сложности, которую также иногда называют описательной сложностью. Формальное определение Колмогоровской сложности задается следующим образом: сложностью строки x является длина минимальной бинарной программы, выводящей строку x. Колмогоровская сложность x при заданном y – это длина наикратчайшей бинарной программы, которая, получая на вход y, выводит x (это обозначается 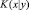 ). Колмогоровская сложность x как длина наикратчайшей бинарной программы без входных данных, выводящая x, обозначается
). Колмогоровская сложность x как длина наикратчайшей бинарной программы без входных данных, выводящая x, обозначается 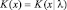 , где λ – отсутствие данных на входе. Данная величина является невычислимой, но ее можно аппроксимировать как длину максимально сжатой версии входной строки [2].
, где λ – отсутствие данных на входе. Данная величина является невычислимой, но ее можно аппроксимировать как длину максимально сжатой версии входной строки [2].
В работе [10] была показана необходимость модификации введенного в [8] нормализованного расстояния сжатия текстов при рассмотрении текстов разной длины. Предложенная модификация позволяет учесть различный объем рассматриваемых текстов; действительно, в случае, когда один из рассматриваемых текстов существенно меньше другого, то он привносит в обобщенный объект существенно меньше информации. Поэтому производится предварительное разделение больших объектов на отдельные части в зависимости от длины наименьшего рассматриваемого текста.
Теория нечеткости
Принцип нечеткой логики использует нечеткие модели при представлении текстовых данных с применением качественных, неточных или неопределенных признаков. Теория нечеткости возникла в связи с попытками смоделировать способность человека принимать решения в условиях неполной информации, а также способности человека к обобщению различных характеристик и свойств.
Принцип нечеткости позволяет учесть сразу два важных момента, которые возникают в задачах анализа текстов, как, впрочем, и при решении многих других проблем:
● естественная неоднозначность при рассмотрении текстовых объектов;
● принципиальная невозможность учесть все возможные факторы и параметры.
Последняя проблема связана со сложностью моделирования текстовых объектов, необходимостью рассмотрения множества глубинных параметров текста. С другой стороны, любой текст сам по себе является моделью некоторой ситуации или возникшего у автора образа, тем самым моделируя текст, производится опосредованная модель процесса человеческого мышления и других особенностей и свойств человеческого мозга.
Любая построенная модель всегда является некоторым приближением реального объекта, в котором выделены лишь некоторые признаки, важные для решения конкретной задачи. Для других задач необходимо рассматривать другую или измененную модель, в которой учтены другие характеристики. При этом никакая, даже самая сложная модель не может абсолютно точно отразить реальную систему, даже простую. Введение некоторых допущений, не важных для решения конкретных задач, помогает составлять и использовать модели реальных объектов. Но при этом при переходе к модели возникает естественная неопределенность (нечеткость), связанная с влиянием «отброшенных» факторов на рассматриваемые в модели.
Неопределенность модели может быть также связана с самим моделируемым объектом – нечеткость в определении (измерении). Неопределенность-случайность отражает распределение объектов по каким-то параметрам, выраженное количественно, отражает случайные воздействия внешних факторов на рассматриваемый объект.
Естественная (природная) нечеткость текстовых данных обусловлена субъективностью использования терминов, синонимией и многозначностью слов, стилистической и жанровой неоднозначностью, а также эволюцией языков, например, проникновением терминов одной научной области в другие.
Использование нечеткого отношения как бинарной функции, определяющей степень выполнения отношения для каждой пары объектов, позволяет формализовать многие реальные явления и задачи при обработке и анализе текстов. Если рассматривать некоторое множество текстов, то для каждой пары может быть вычислена степень близости, например, на основе понятия Колмогоровской сложности и определения степени сжатия объединенных объектов. Тогда полученную матрицу расстояний можно рассматривать как нечеткое бинарное отношение, заданное на множестве текстовых объектов. На рис. 3 приведен фрагмент таблицы, построенной для художественных текстов русских авторов, элементы которой могут быть интерпретированы как значения нечеткого отношения близости объектов. В работе [5] рассмотрена задача нечеткого разделения пользователей социального сообщества в сети Интернет путем выявления характерных признаков оставленных ими сообщений.
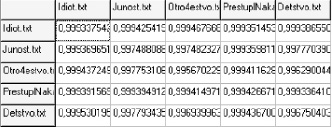
Рис. 3. Пример матрицы близости текстовых объектов
Обобщение с единых позиций теоретических аспектов моделирования текстов позволяет эффективно решать основные задачи их обработки: задачи кластеризации, классификации и идентификации. При разработке и проектировании систем анализа текстовых структур целесообразно использовать совокупность моделей текстов, характеризующую различные параметры и особенности текстов на разных уровнях иерархии и учитывающую природную нечеткость. При решении конкретных задач из всей совокупности выбирается только определенный спектр моделей, наилучшим образом отвечающих поставленным задачам. Рассмотренные теоретические аспекты могут найти применение в задачах развития и совершенствования информационно-поисковых систем, а также систем информационной безопасности, в частности при решении задач идентификации Интернет-сообщений и определении авторства исходных кодов программ.
Рецензенты:
Баландин Д.В., д.ф.-м.н., профессор, заведующий кафедрой численного и функционального анализа, Нижегородский государственный университет им. Н.И. Лобачевского, г. Нижний Новгород;
Федосенко Ю.С., д.т.н., профессор, заведующий кафедрой «Информатика, системы управления и телекоммуникаций», Волжский государственный университет водного транспорта, г. Нижний Новгород.
Работа поступила в редакцию 17.04.2015.Библиографическая ссылка
Ломакина Л.С., Суркова А.С. ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ КОНЦЕПТУАЛЬНОГО АНАЛИЗА И МОДЕЛИРОВАНИЯ ТЕКСТОВЫХ СТРУКТУР // Фундаментальные исследования. – 2015. – № 2-17. – С. 3713-3717;URL: https://fundamental-research.ru/ru/article/view?id=37843 (дата обращения: 26.04.2024).