



Вся сегодняшняя жизнь современного человека буквально пропитана вычислительной техникой: компьютерами и создаваемыми на их базе вычислительными системами (ВС). Они проникли повсеместно: в бытовой технике, приборах, устройствах связи и т.д. Список можно продолжать долго. Среди всех ВС особняком стоят многопроцессорные вычислительные системы (МПВС), которые активно используются для трудоемких вычислений, например, при моделировании сложных процессов и других научных расчетов, которым необходимы колоссальное быстродействие и слаженная работа подсистемы «процессор-память».
Основной целью, которую преследует эта статья является проработка функциональной организации и алгоритмов работы аппаратно реализованного буферного устройства памяти МПС с общей шиной. Описываемое здесь устройство необходимо, в первую очередь, для быстрого доступа к памяти и разгрузки процессоров. В результате применения данного модуля снижается загрузка памяти, повышается пропускная способность подсистемы «процессор-память» и возрастает быстродействие МПВС в общем и целом.
Представляемая статья в целом носит исследовательский характер. В ходе изучения предметной области был проанализирован ряд литературных источников [1, 9, 10] с целью поиска незатронутых вопросов и нерешенных проблем. Ряд проблемных вопросов, связанных с возможностью аппаратной реализации буферного устройства памяти многопроцессорных систем для разгрузки подсистемы «процессор-память», не нашел должного отражения в существующих публикациях, частично проблемные вопросы были проанализированы в работах [2–7, 10].
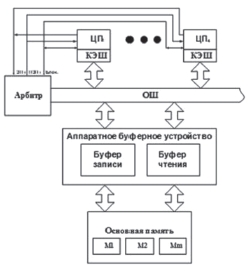
Рис. 1. Четырехпроцессорная система с АБУ памяти
Целью работы является описание рассмотрения возможных алгоритмов функционирования аппаратно реализованного буферного устройства (АБУ) памяти МПВС с интерфейсом «общая шина» (ОШ), включающей в свой состав 4 процессора (ЦП) (рис. 1). Данный вопрос сегодня является актуальным ввиду глобальной информатизации и практически повсеместном оперировании колоссальными объемами данных. Для достижения поставленной цели в статье решаются задачи по определению структуры устройства и принципов и алгоритмов его функционирования. В существующих МПВС на занятие ОШ единовременно могут претендовать несколько устройств, однако в любой момент времени это возможно только одному из них. Для исключения возможных конфликтов ОШ должна выбирать механизмы арбитража запросов и правила предоставления шины одному конкретному устройству из запросивших [8].
ОШ взята в соответствии со спецификацией AMBA [11], которая разработана для создания высокопроизводительных систем. Возможная структура и принципы функционирования АБУ показаны в работах [3–5]. Здесь подробно остановимся на функциональной организации и алгоритмах работы АБУ.
При написании VHDL-кода схемной реализации как таковой не получается, если не придерживаться описания конкретного элемента для VHDL (например, описание функционирования регистра, счетчика, дешифратора и т.п.). Но все же попробуем выделить некоторые функциональные блоки (рис. 2):
– блок добавления транзакции в очередь чтения;
– блок добавления транзакции в очередь записи;
– блок увеличения указателя на голову буфера чтения и увеличения очереди чтения;
– блок увеличения указателя на голову буфера записи и увеличения очереди записи;
– блок поиска данных в буфере записи при совпадении адресов с буфером чтения;
– блок чтения из памяти по указанному адресу;
– блок увеличения указателя на хвост очереди обработанных сообщений;
– блок записи в память по указанному адресу;
– блок увеличения указателя на хвост буфера записи;
– блок выдачи данных ЦП, инициировавшему запрос на чтение.
На рис. 2 все блоки показаны в общем виде.
Блок добавления транзакции в очередь чтения работает следующим образом. На внутренний регистр RGA1 поступает 32-разрядный адрес от ЦП, по которому должны быть найдены данные. На регистр RGMID подается 2-разрядный идентификатор ЦП (принимает значение от 0 до 3 по числу ЦП в системе). Разрешающим сигналом для работы данных регистров является комбинация сигналов.
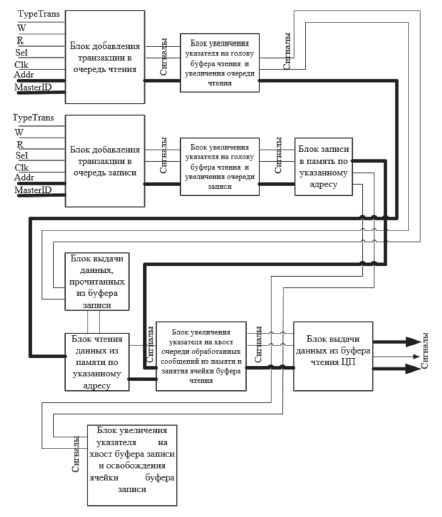
Рис. 2. Функциональные блоки АБУ памяти
Блок добавления транзакции в очередь записи работает следующим образом. На внутренний регистр RGA2 поступает 32-разрядный адрес от ЦП, по которому должны быть записаны данные. На регистр RGD подаются 32-разрядные данные от ЦП. Разрешающим сигналом для работы данных регистров является комбинация сигналов.
Блок увеличения указателя на голову буфера чтения и увеличения очереди чтения работает следующим образом. Всю очередь заявок представим состоящей из «головы очереди», «хвоста очереди» и указателя на ячейку в данный момент времени. При добавлении следующей заявки в очередь чтения «голова» увеличивается на единицу и вместе с тем увеличивается сама очередь чтения. Этот блок можно представить в виде счетчиков.
Блок поиска данных в буфере записи при совпадении адресов с буфером чтения можно реализовать на 32-разрядном компараторе, на один вход которого подается адрес, выставленный ЦП в буфере чтения, на другой последовательно подаются адреса из буфера записи. При совпадении адресов ЦП возвращаются данные из буфера записи. Если же адреса не совпали, т.е. ассоциативный поиск не дал результатов, то необходимо обратиться к памяти по нужному адресу. Это действие производит следующий блок.
Блок чтения из памяти по указанному адресу работает следующим образом. Из 32-разрядного регистра, в котором хранится адрес, выставленный ЦП, этот адрес поступает на выход АБУ, на адресные входы памяти. Два старших разряда адреса используются для выбора модуля памяти, откуда необходимо прочитать данные по указанному адресу. Подается сигнал чтения из памяти MemR, который будет держаться в единице на протяжении 50 ns – время поиска данных в памяти по указанному адресу и чтение в буфер. Данные сохраняются в регистре данных в буфере чтения, и когда ЦП, который выставлял адрес на чтение, вновь подключится к ОШ для получения данных, из буфера чтения им будут считаны необходимые данные, предназначаемые ему. Выдается сигнал Split (номер ЦП).
Блок увеличения указателя на хвост очереди обработанных сообщений работает следующим образом. Когда произошла операция чтения из памяти, то данные не сразу выдаются ЦП. Вначале создается так называемая «очередь обработанных сообщений». С каждой новой обработанной транзакцией увеличивается очередь сообщений. Блок можно реализовать на счетчике.
Блок записи в память по указанному адресу работает следующим образом. Из 32-разрядных регистров, в которых хранятся адрес и данные в буфере записи, происходит запись в память. Здесь также два старших разряда адреса используются для выбора модуля памяти, куда будут записываться данные. Подается сигнал записи в память MemW, который будет держаться на протяжении 10 ns – время записи данных в память.
Блок увеличения указателя на хвост буфера записи работает следующим образом. При записи в память указатель на хвост буфера увеличивается на единицу с каждой обработанной транзакцией. После этого в буфере записи освобождается одна ячейка.
Блок выдачи данных ЦП, инициировавшему запрос на чтение, работает следующим образом. Как только очередь готовых заявок сформирована, т.е все заявки очереди обработаны, данные из памяти помещены в буфер чтения, то ЦП могут забирать заявки, предназначенные им. Данные из регистров поступают на выход DataRead и ЦП считывает данные.
Теперь покажем вариант алгоритма функционирования АБУ. Представим подсистему «процессор-память» как две подсистемы: «процессор-АБУ» и «АБУ-память». Опишем алгоритм функционирования подсистемы «процессор-АБУ». Вначале ЦП проверяет линию блокировки и определяет, свободна либо занята ОШ в данный момент времени. Допустим, высокий потенциал на линии блокировки соответствует состоянию, при котором ОШ свободна. Если же опрашивающие линию блокировки ЦП обнаруживают там высокий потенциал, они отправляют запросы в шинный арбитр. ЦП с наивысшим приоритетом получит сигнал, подтверждающий запрос. После захвата ЦП ОШ выбирается тип операции: чтение или запись. В случае выполнения операции записи, буфер записи проверяется на наличие свободного места и в случае, если он полон, ЦП переводится в режим ожидания, где находится до появления свободной ячейки. В случае, если место есть, происходит запись адреса и данных, после чего ЦП освобождает ОШ. В случае выбора операции чтения, сначала буфер чтения проверяется на наличие свободного места и в случае их отсутствия ЦП переводится в режим ожидания пока не появятся свободная ячейка. Если свободная ячейка имеется, происходит запись адреса, по которому должны быть предоставлены данные для чтения. После процедуры физического чтения из памяти или поиска в ассоциативной памяти буфера записи по выставленному адресу считываются данные в буфер чтения. АБУ оповещает ЦП, которому подготовлены считанные данные, о готовности, и он забирает их из АБУ.
Опишем возможный алгоритм работы подсистемы «АБУ-память». Вначале выбирается тип операции: чтение или запись. При выборе операции записи осуществляется запрос j-го модуля памяти, куда будут записываться данные, пересланные в АБУ из ЦП. Далее j-й модуль памяти проверяется на занятость, и если он занят, подсистема переходит в режим ожидания, если свободен, происходит запись данных по нужному адресу. Далее модуль памяти, как и одна ячейка буфера записи освобождаются. При выполнении операции чтения запрашивается k-й модуль памяти, откуда будут считываться данные в АБУ, для дальнейшей передачи их соответствующему ЦП. После этого проверяется k-й модуль памяти на занятость, и если он занят, подсистема переходит в режим ожидания, если свободен, происходит чтение данных по нужному адресу. После этого считанные данные записываются в ячейку буфера чтения. Затем модуль памяти высвобождается, а АБУ оповещает запросивший ЦП о выполнении операции.
По приведенным алгоритмам работы АБУ в среде ISE WebPack устройство было промоделировано и были получены диаграммы, показанные на рис. 3, по которым можно говорить о правильном функционировании устройства согласно описанным выше алгоритмам.

Рис. 3. Временные диаграммы работы АБУ памяти
Выводы
В работе затронуты вопросы функциональной организации аппаратного буферного устройства и его алгоритмов работы. Рассматриваемое устройство отличается от ранее существующих тем, что ранее в МПС задача решалась применением памяти с архитектурой NUMA, либо памяти архитектуры UMA с чередованием адресов, что не позволяло использовать режим расщепления транзакций на ОШ.
В результате использования АБУ, реализованного на ПЛИС, понижается загрузка памяти, возрастает пропускная способность подсистемы «процессор-память» и быстродействие всей МПС в целом.
Работа выполнена при финансовой поддержке РФФИ (грант № 16-07-00012).